一 、认识EFK
我们常常听到的都是Elastic stack,也就是ELK(ElasticSearch + LogStash + Kibana),通过logstash收集日志数据,存到ElasticSearch,最后通过kibana进行统计分析。但是logstash是jvm跑的,资源消耗比较大,所以使用更加轻量的filebeat来搭建日志收集系统。
二、下载相关镜像
docker pull elasticsearch:7.8.0
docker pull kibana:7.8.0
docker pull logstash:7.8.0
docker pull docker.elastic.co/beats/filebeat:7.8.0
三、搭建EFK日志系统
创建一个efk文件夹, 后面的配置文件都放在里面
mkdir -p /data/efk
3.1 安装elasticsearch
创建一个elasticsearch.yml文件
vi /data/elk/elasticsearch.yml
在里面添加如下配置:
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# 访问ID限定,0.0.0.0为不限制,生产环境请设置为固定IP
transport.host: 0.0.0.0
# elasticsearch节点名称
node.name: node-1
# elasticsearch节点信息
cluster.initial_master_nodes: ["node-1"]
# 下面的配置是关闭跨域验证
http.cors.enabled: true
http.cors.allow-origin: "*"
创建并启动elasticsearch容器
docker run -dit \
-p 9200:9200 \
-p 9300:9300 \
-e TZ=Asia/Shanghai \
-e ES_JAVA_OPTS="-Xms512m -Xmx512m" \
--name=elasticsearch \
-v /data/elk/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /data/elk/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.8.0
参数说明:
ES_JAVA_OPTS:指定堆内存为512m(因为不指定的话Es的初始内存默认是1G,你的机器内存不够的话就OOM了,根据自己具体环境配置更改大小)
可能遇到的问题
1.启动成功后,过了一会就停止
因为elasticsearch在启动的时候会进行一些检查,比如最多打开的文件的个数以及虚拟内存区域数量等等.我们还需要系统调优
修改/etc/security/limits.conf ,添加如下内容:
* soft nofile 65536
* hard nofile 65536
nofile是单个进程允许打开的最大文件个数 soft nofile 是软限制 hard nofile是硬限制
修改/etc/sysctl.conf,追加内容
vm.max_map_count=655360
限制一个进程可以拥有的VMA(虚拟内存区域)的数量
执行下面命令 修改内核参数马上生效,之后重启服务器和docker服务
sysctl ‐p
3.2 安装kibana
kibana主要用于对elasticsearch的数据进行分析查看。注意选择的版本必须和elasticsearch的版本相同或者低,建议和elasticsearch的版本相同,否则会无法将无法使用kibana。
创建一个kibana.yml配置文件,在里面编写如下配置:
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://elasticsearch的IP:9200"]
# 操作界面语言设置
i18n.locale: "zh-CN"
创建并启动kibana容器
docker run -dit \
--name kibana \
-p 5601:5601 \
-v /data/elk/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:7.8.0
启动成功后访问5601端口即可进入kibana管理界面。
3.3 安装filebeat
创建配置文件filebeat.docker.yml,内容如下:
filebeat.inputs:
- type: log
enabled: true
##配置你要收集的日志目录,可以配置多个目录
paths:
- /var/lib/docker/containers/*/*.log
##配置多行日志合并规则,已时间为准,一个时间发生的日志为一个事件
multiline.pattern: '^\d{4}-\d{2}-\d{2}'
multiline.negate: true
multiline.match: after
## 设置kibana的地址,开始filebeat的可视化
setup.kibana.host: "http://kibana的IP:5601"
setup.dashboards.enabled: true
output.elasticsearch:
hosts: ["http://elastic的IP:9200"]
index: "filebeat-%{+yyyy.MM.dd}"
setup.template.name: "tuling-log"
setup.template.pattern: "tuling-log-*"
json.keys_under_root: false
json.overwrite_keys: true
##设置解析json格式日志的规则
processors:
- decode_json_fields:
fields: [""]
target: json
建立好配置文件之后,启动filebeat容器
docker run -d \
--user=root \
-v /data/elk/filebeat.docker.yml:/usr/share/filebeat/filebeat.yml:ro \
-v /var/lib/docker/containers:/var/lib/docker/containers:ro \
-v /var/run/docker.sock:/var/run/docker.sock:ro \
-e -strict.perms=false \
--name filebeat \
docker.elastic.co/beats/filebeat:7.8.0
这里 -v 就是挂在目录的意思就是将自己本地的目录挂载到容器当中,第一个挂载映射的是配置文件,第二个是要收集的日志目录,如果不挂载日志目录的话,filebeat是不会收集日志的,因为在容器里面根本找不到要收集的路径。
启动之后通过docker logs 查看日志,可以看到日志已经收集了

然后去kibana查看是否有filebeat的索引生成。
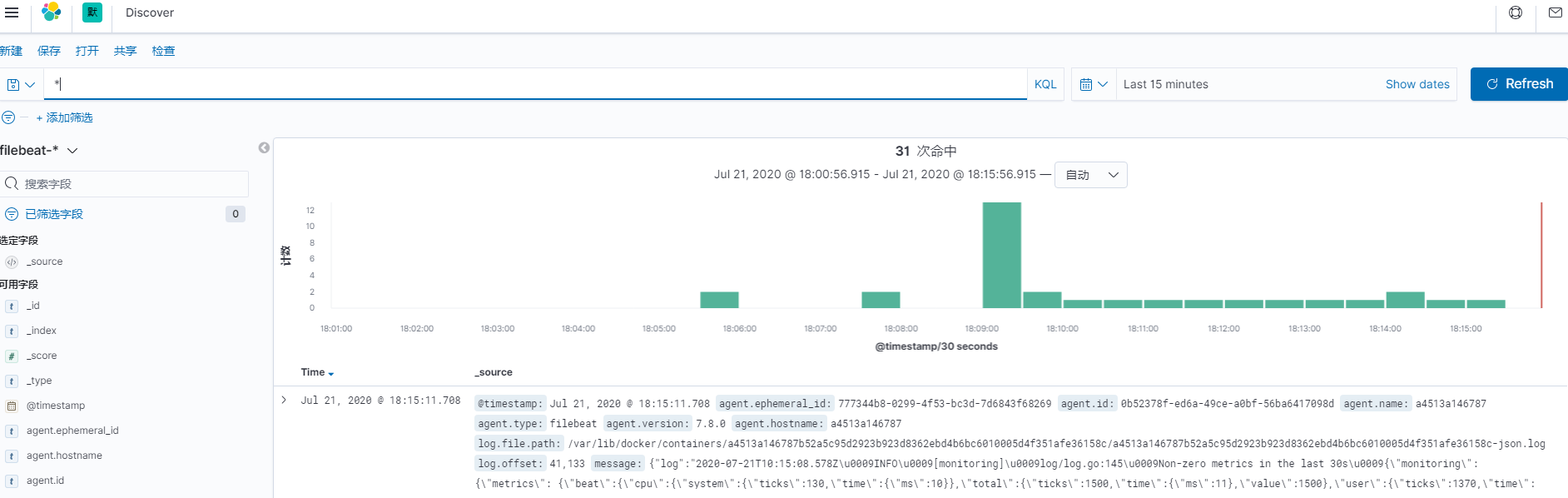
可以通过搜索或者日期筛选,字段筛选,等等各种操作查看你需要的日志信息。
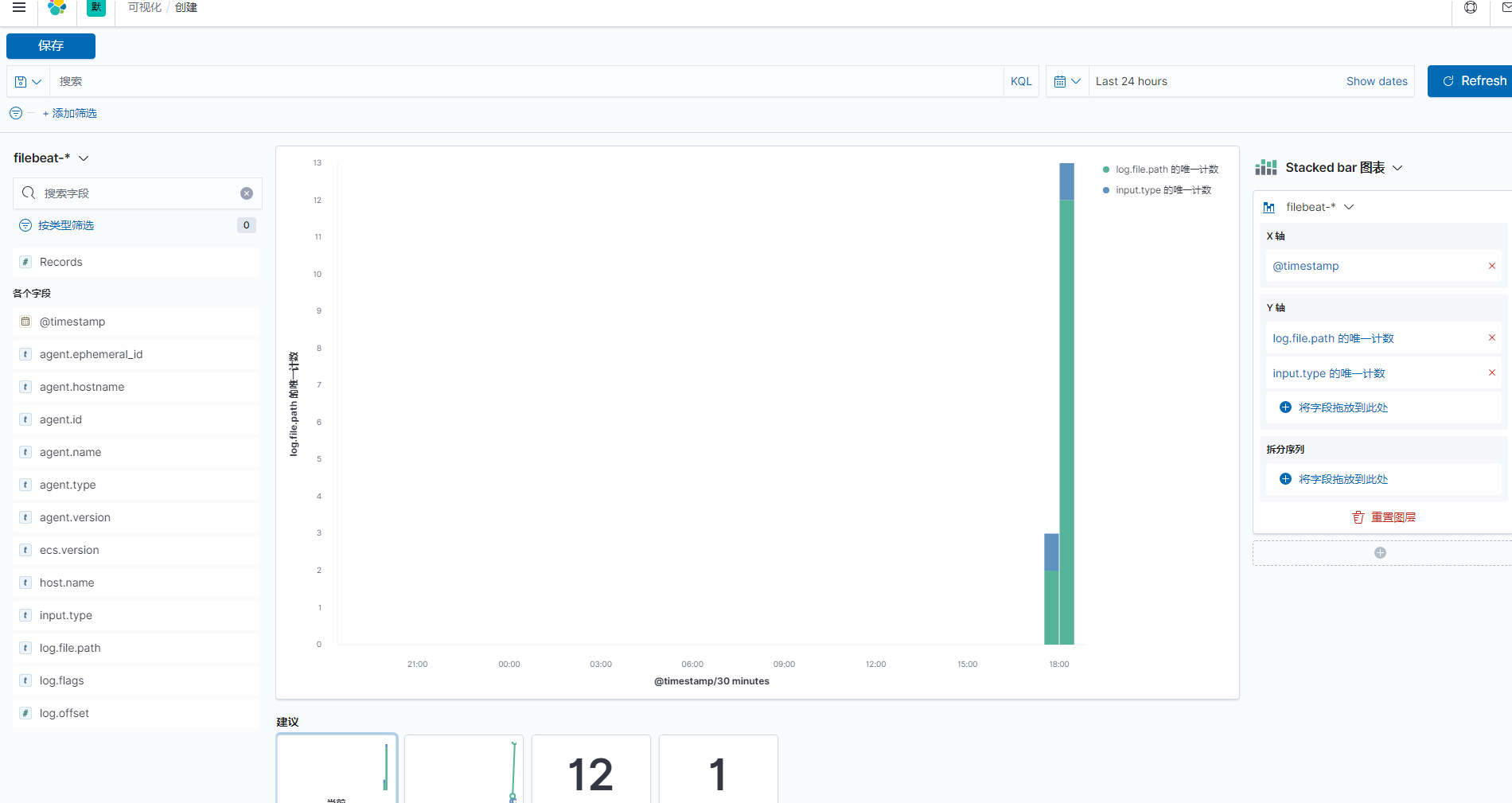
也可以,在可视化统计页面,按照自己的需求可视化展示统计信息。