传统日志处理
说到日志,我们以前处理日志的方式如下:
日志写到本机磁盘上
通常仅用于排查线上问题,很少用于数据分析
需要时登录到机器上,用grep、awk等工具分析
那么,这种方式有什么缺点呢?
第一, 它的效率非常低,因为每一次要排查问题的时候都要登到机器上去,当有几十台或者是上百台机器的时候,每一台机器去登陆这是一个没办法接受的事情,可能一台机器浪费两分钟,整个几小时就过去了。
第二, 如果要进行一些比较复杂的分析,像grep、awk两个简单的命令不能够满足需求时,就需要运行一些比较复杂的程序进行分析。
第三, 日志本身它的价值不光在于排查一些系统问题上面,可能在一些数据的分析上,可能利用日志来做一些用户的决策,这也是它的价值,如果不能把它利用起来,价值就不能充分的发挥出来。
所以,现在很多公司会采用集中式日志收集的日志处理方式,我们会把日志分布式收集,集中来存储,我们会在所有机器上面把日志都收集起到一个中心,在中心里面做一个日志全文索引搜索,可以通过一个界面去查询,同时这个日志系统后端可以对接一些更复杂的数据处理系统,可以对接监控、报警系统,对接数据挖掘数据分析系统,充分发挥日志的价值。
Docker的日志处理
使用过Docker的人尤其是使用过容器编排系统,比如说docker swarm和 kubernetes。
容器编排跟传统的布置方式是不一样的,在容器编排里面,资源分配应用跑到哪台机器上面的调度是由容器层来做的,所以你事先不知道你的容器应用会跑到哪台机器上面;还有自动伸缩,根据负载自动增加或者减少容器数量;另外,在整个运行过程中,系统发生一些情况时,比如说你的容器宕掉了,容器服务会自动把容器应用迁到其他的机器上去,整个过程非常动态,如果像传统方式去配制日志的收集工具,从一台机器上面收集某一个应用,在这个动态下面,很难用原来的方式去配置。
基于这些特点,在Docker的日志里面, 我们只能够采用中心化的日志收集方案,你已经没办法再像原来登到一台机器上面去看它的日志是什么,因为你不知道它其实在哪个机器上面。
stdout
Docker的日志我们可以把它分成两类,一类是stdout标准输出,另外一类是文件日志。stdout是写在标准输出里面的日志,比如你在程序里面,通过print或者echo来输出的时候,这种输出标准在linux上面其实是往一个ID为零的文件表述书里面去写;另外的就是文件日志,文件日志就是写在磁盘上的日志,一般来说我们会在传统的应用里面会用得多一些。
在Docker的场景里面,目前比较推崇这种标准输出的日志,标准输出日志的原理在于,当在启动进程的时候,进程之间有一个父子关系,父进程可以拿到子进程的标准输出。拿到子进程标准输出的后,父进程可以对标准输出做所有希望的处理。
例如,我们通过exec.Command启动了一个命令,带一些参数,然后就可以通过标准的pipeline拿到标准输出,后面就可以拿到程序运行过程中产生标准输出。 Docker也是用这个原理来拿的,所有的容器通过Docker Daemon启动,实际上属于Docker的一个子进程, 它可以拿到你的容器里面进程的标准输出,然后拿到标准输出之后,会通过它自身的一个叫做LogDriver的模块来处理,LogDriver就是Docker用来处理容器标准输出的一个模块。 Docker支持很多种不同的处理方式,比如你的标准输出之后,在某一种情况下会把它写到一个日志里面,Docker默认的JSON File日志,除此之外,Docker还可以把它发送到syslog里面,或者是发送到journald里面去,或者是gelf的一个系统。
怎么配置log driver呢?
用Docker来启动容器的话,你有两种方式来配置LogDriver:
第一种方式是在Daemon上配置,对所有的容器生效。你配置之后,所有的容器启动,如果没有额外的其他配制,默认情况下就会把所有容器标准输出全部都发送给Syslog服务,这样就可以在这个Syslog服务上面收集这台机器上的所有容器的标准输出
{
"log-driver": "syslog"
}
第二种方式是在容器上配置,只对当前容器生效。如果你希望这个配置只对一个容器生效,不希望所有容器都受到影响,你可以在容器上面配置。启动一个容器,单独配置它自身使用的logdriver。
docker run -it --log-opt mode=non-blocking --log-opt max-buffer-size=4m alpine ping 127.0.0.1
图中列表是docker支持的 logdriver
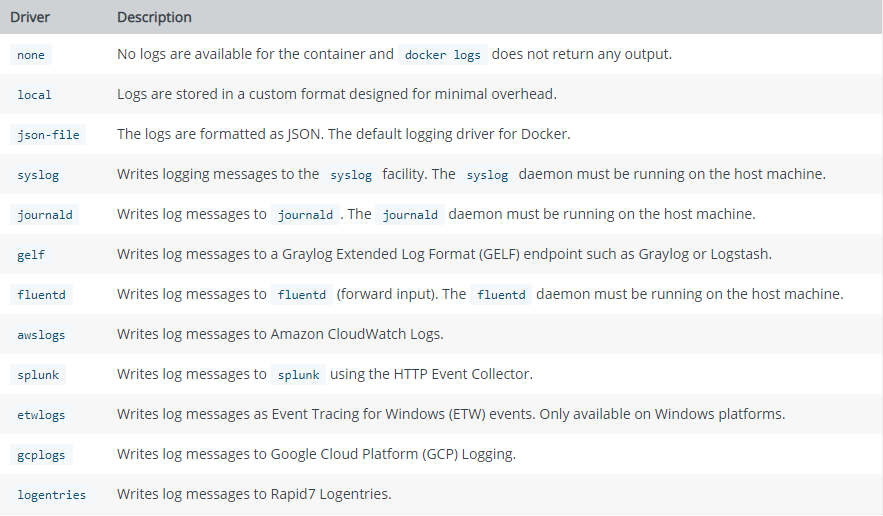
文件日志
对于stdout的这种日志,在Docker里面现在处理起来还是比较方便的,如果没有现成Logdriver的也可以自己实现一个,但是对于文件日志处理起来就没有这么简单了。如果在一个容器里面写了日志,文件位于容器内部,从宿主机上无法访问,的确你是可以根据Docker用的devicemapper、overlayfs访问到它里面的一个文件,但是这种方式跟Docker的实现机制是有关系的,将来它如果改变,你的方案就失效了;另外,容器运行非常动态,日志收集程序难以配置,如果有一个日志收集的程序,在机器上面配置要收集哪个文件,它的格式是什么样子的、发送到哪儿?因为一台机器上面容器是一直在动态变的,它随时可能在增加一个或者删除一个,事先你并不知道这台机器上会跑了多少个容器,他们的配置是怎么样子的,他们的日志是写在哪儿的,所以没办法预先在一台机器上面把这个采集程序配好,这就是文件收集比较难的两个地方。
最简单的一个方案,给每个容器弄一个日志采集进程,这个进程跑到容器里面,就可以解决以上的两个问题,第一因为它跑到容器里面,就可以访问到容器里面所有的文件,包括日志文件;第二它跟容器在一起,当容器启动的时候,收集日志的进程也启动了,当容器销毁的时候,进程也就被销毁掉了。
这个方案非常简单,但是其实会有很多的缺点:
第一, 因为每个容器都有一个日志的进程,意味着你的机器上面有100个容器,就需要启动一百个日志设备的程序,资源的浪费非常厉害。
第二, 在做镜像的时候,需要把容器里面日志采集程序做到镜像里面去,对你的镜像其实是有入侵的,为了日志采集,不得不把自己的日志程序再做个新镜像,然后把东西放进去,所以对你的镜像过程是有入侵性的。
第三, 当一个容器里面好多个进程的时候,对于容器的资源管理,会干扰你对容器的资源使用的判断,包括对于在做资源分配和监控的时候,都会有一些这样的干扰。